Smooth-label
- CV
- 2021-05-04
- 461热度
- 0评论
When Does Label Smoothing Help
Contribution
- 介绍了一种基于倒数第二层激活的线性投影可视化方法,这种方法提供了一种直观的表示关于倒数第二层使用平滑标签和非平滑标签训练的区别
- 证明了平滑标签方法可以隐式的校准模型,所以预测的置信度会与预测的准确度对齐
- 证明了平滑标签会弱化知识蒸馏的效果,如果教师模型通过平滑标签进行训练的话,那么学生模型表现会十分的差,造成这一现象的原因是由于logits信息丢失造成的
Preliminaries
假设我们将倒数第二层神经网络的激活函数写为softmax函数:
$$
p_k=\frac{e^{x^Tw_k}}{\sum_{l=1}^Le^{x^Tw_l}}
$$
式中\(p_k\)对应模型第\(k\)类的置信度,\(w_k\)代表模型的权重和偏置,\(x\)为倒数第二层(包括激活曾)的输出;那么在通常训练方式下,做分类任务时它们的损失函数应该为:
$$
H(y,p)=\sum_{k=1}^K-y_klog(p_k)
$$
那么\(y_k\)的真实标签不是1就是0;然而平滑标签的方式引入了新的标签方式
$$
y_k^{LS}=y_k(1-\alpha)+\alpha/K
$$
Penultimate layer representations
使用平滑标签的方式进行训练的结果其预测的真实种类和错误种类的相差程度主要是依赖与参数\(\alpha\)的设置。而不使用平滑标签的方法,网络分类所得结果真是类别和错误类别输出差距会很大并且错误类别之间输出差距同样会很大。
直观的理解网络第k类的输出结果\(x^Tw_k\)可以理解为倒数第二层激活输出\(x\)与\(w_k\)之间的欧氏距离
$$
||x-w_k||^2=x^Tx-2x^Tw_k+w_k^Tw_k
$$
由于每个类别都会有\(w_k\)并且在计算的时候为常数,在计算softmax的时候主要考虑的是第一项;为了观察标签平滑的这一特性,我们基于以下步骤提出了一种新的可视化方案:(1)选择三个类别,(2)找到穿过这三个类别参数的平面的正交基础,(3)将这三个类的倒数第二层激活值投影到该平面上。此可视化效果以二维方式显示了激活如何围绕模板聚类,以及标签平滑如何在示例与其他类的聚类之间的距离上实现结构。
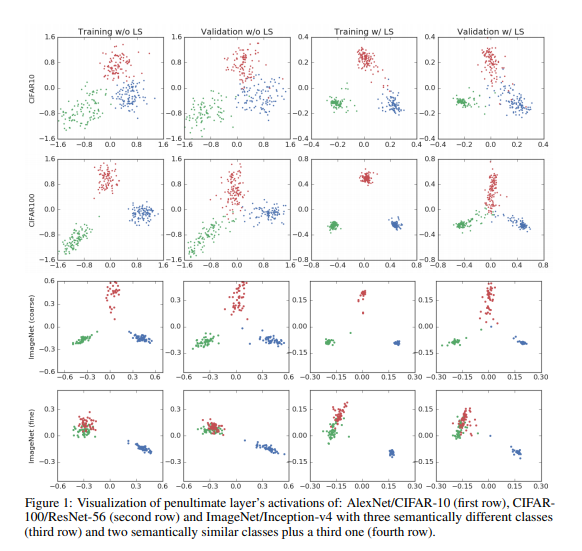
Implicit model calibration
本章主要探讨平滑标签是否可以矫正模型提高模型的准确度,为了评估校准的能力,作者计算了校准误差,他们证明了简单的后处理科技减少误差校准网络:网络模型的参数整体的缩放可以减少校准误;并且使用平滑标签进行训练仍然是可以减小误差的,这样就不需要再调整参数了。
Image classification
首先研究了分类模型的校准,如下图(左)所示res-56以cifar为数据集进行训练(右)再ImageNet上训练,虚线代表的是理想情况下模型的准确率与置信度之间的关系,如果没有参数的缩放且使用常规的编码方式,那么模型总是过于自信期望准确度总是高于模型预测的置信度。但是如果使用缩放参数或者平滑标签的方法就可以得到很好的效果。而再imageNet上训练的记过可以发现标签平滑方式是远好于参数缩放的方式的。
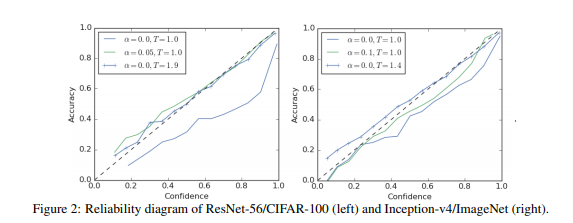
Machine translation
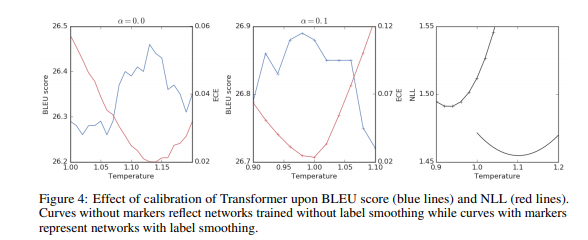
在翻译任务中将英语翻译成德语之后其性能曲线如下图所示(模型结构使用的是transformer)
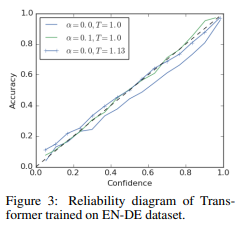
尽管标签平滑能够提高BLEU得分(单纯进行temperature参数的缩放是不能弥补的),但是会导致负对数似然函数变差。如下图所示红线为校准误差,蓝线为BLUE分数;最右边的曲线图中带哟标记点的为标签平滑的结果
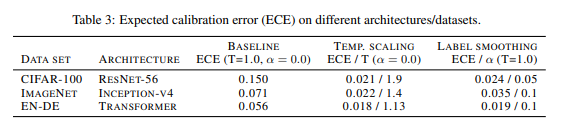
下表为图片分类和机器翻译的结果展示:
知识蒸馏
目前作者并不熟悉知识蒸馏,因此有些知识依靠翻译来硬着头皮理解 ----2021.05.04
本文发现,即使使用标签平滑处理提高了教师网络的准确性,但与使用普通标签进行培训的教师相比,使用标签平滑处理的教师也会产生较差的学生网络。
在知识蒸馏中使用加权和来代替交叉熵损失函数:
$$
(1-\beta)H(y,p)+\beta H(p^t(T),p(T))
$$
式中\(p_k(T)\)和\(p_k^t(T)\)分别是学生网络和教师网络经过temperature参数缩放后的输出,\(\beta\)作用为拟合硬目标和逼近软化的教师网络。可以将温度视为夸大错误答案概率之间差异的一种方式
作者在本章的实验中训练了一个resnet50的教师网络以及对Alexnet网络进行知识蒸馏,作者关注了以下几点
- 教师网络的准确度与标签平滑因子的关系
- 学生无需蒸馏的基线准确度与标签平滑因子的函数关系
- 通过参数缩放来控制蒸馏后学生的准确度,以控制教师网络提供的目标的平滑度(经过硬目标训练的老师)
- 在固定temperature参数下蒸馏后,学生的准确度(\(T = 1.0\),并且老师接受了标签平滑训练,以控制老师提供的目标的平滑度)
下图显示出了该蒸馏实验的结果。我们首先比较未经蒸馏训练的教师网络(蓝色实线,顶部)和学生网络(浅蓝色实线,底部)的性能。对于此特定设置,增加\(α\)可以将教师的准确性提高到\(α= 0.6\)的值,而标签平滑会稍微降低学生网络的基准性能。
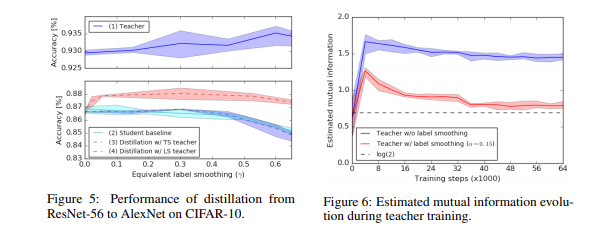
作者使用硬标签训练了teacher model 并基于不同温度进行蒸馏,且分别计算了不同温度下的 y 值,用红色虚线表示。实验发现,所有未使用标签平滑技术的模型效果都优于使用标签平滑技术的模型效果。最后,作者将使用标签平滑技术训练的具有更高准确度的teacher model 的知识蒸馏入student model ,并用蓝色虚线进行了表示。可以发现,模型效果并未得到显著提升,甚至有所降低。