HRNet
- CV
- 2021-05-31
- 494热度
- 0评论
Deep High-Resolution Representation Learning for Human Pose Estimation
Introduction
本篇文章提出了HRNet结构可以在整个网络过程中保持图片较高的分辨率,以高分辨率子网作为第一步,逐步将从高到低的分辨率子网添加以形成更多的网络阶段,然后将多分辨率子网并行连接。通过在整个过程中重复地在并行多分辨率子网中交换信息来进行多尺度融合。如下图所示:
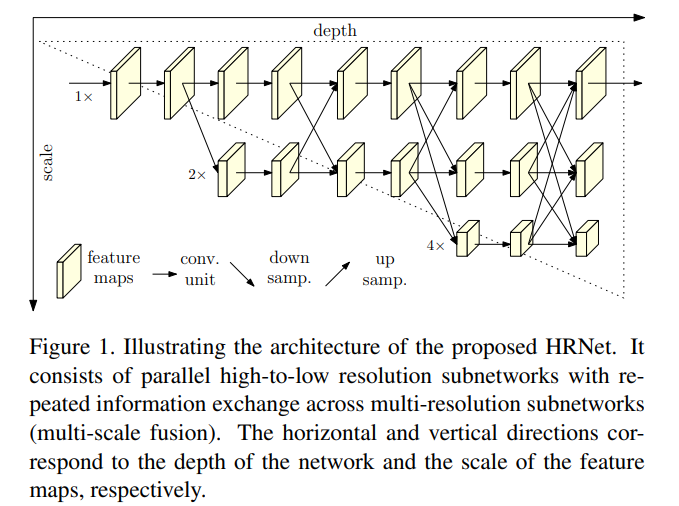
与现存的结构相比,本次提出的结构有两点好处:
- 本篇论文提出的模型结构是以并行的方式而不是串行的方式连接由高到低的子网,因此可以一直保存高分辨率,而不是再从低分辨率恢复到高分辨率
- 现有的backbone融合都是将低级和高级的特征图进行融合以弥补各自所带来的问题,而本篇论文中提出的方法是执行重复的多尺度融合,以借助相同深度和相似水平的低分辨率表示增强高分辨率表示,反之亦然。
Approach
suqential multi-resolution subnetwork
现存的人体姿态估计网络都是分辨率由高到低顺序排列,可以由下图表示:
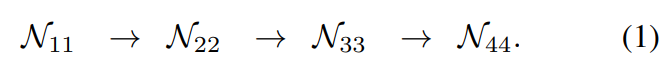
其中\(N_{sr}\)中s代表的是阶段,r代表的是分辨率\(\frac{1}{2^{r-1}}\)(可以理解为stride的倒数)
Parallel multi-resolution subnetwork
在上述结构的基础上,作者先以高分辨率网络为第一阶段,然后逐渐由高到低加入分辨率网络组成新的阶段,然后将多分辨率子网络并行连接。这样下一级并行子网络中包含前一级的分辨率以及一个新的较低的分辨率。

Repeated multi-scale fusion
作者引入了跨行并行子网交换单元,以便每个子网可以重复接收来自其它并行子网的信息。接下来举个例子,将第三阶段分成三个交换块每个交换块包含三个并行卷积单元和一个跨行的交换单元。其中C_{sr}^b代表在阶段s中第b个块中分辨率为r的卷积单元
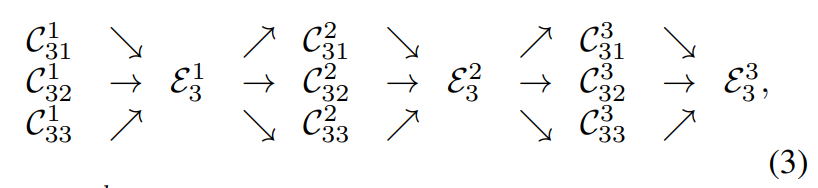
下图揭示了交换单元
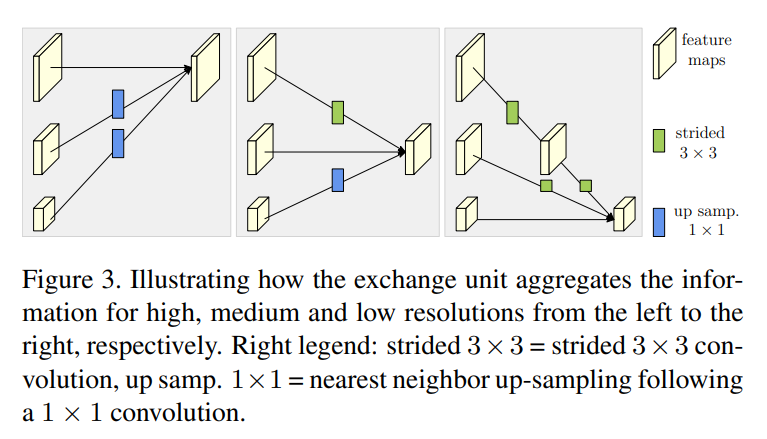
每一个阶段内的输出可以表示为
$$
Y_k=∑_{i=1}^sa(X_i,k)
$$
而在每一阶段之间的交换单元可以表示为:
$$
Y_{s+1}=a(Y_s,s+1)
$$
上面两式中X的下标代表分辨率,\({X_1,X_2,...,X_s}\),输出的特征图为\(Y_1,Y_2,...Y_s\),其中函数\(a(X_i,k)\)代表的是特征图X_i从分辨率i映射到k,下采样的话采用的是3*3卷积核机型步长为2的下采样,上采样的话是最邻近插值法后接1*1卷积进行上采样,亦或者是恒等变化。
Network instantiation
包含四个阶段有四个并行子网络,他们的分辨率逐渐减半并且通道数逐渐加深,第一阶段包含4个残差单元然后跟上一个3*3的卷积来降低特征图的通道数,第2,3,4阶段分别包含1,4,3个交换模块,每一个交换模块包含4个res unit每一个unit包含两个3*3卷积和一个交换单元,所以一共有8个交换单元