S2ANet
- CV
- 2021-08-14
- 412热度
- 0评论
Align Deep Features for Oriented Object Detection
Introduction
作者指出二阶段的检测模型在生成水平候选区域,往往会出现对应多个目标的情况出现,但是如果选择铺设任意方向的anchor的话,那么计算量耗费是十分惊人的。所以相较于二阶段的网络模型,本篇论文主要讨论单阶段模型的可行性。首先给出了单阶段的问题:
- 启发式定义anchor的质量很低,不能覆盖对象,导致对象和anhcor之间没有对齐。
- 来自主干网络的卷积特征通常与固定的感受野轴对齐,但是航拍的图像中的目标大部分都不是这样的
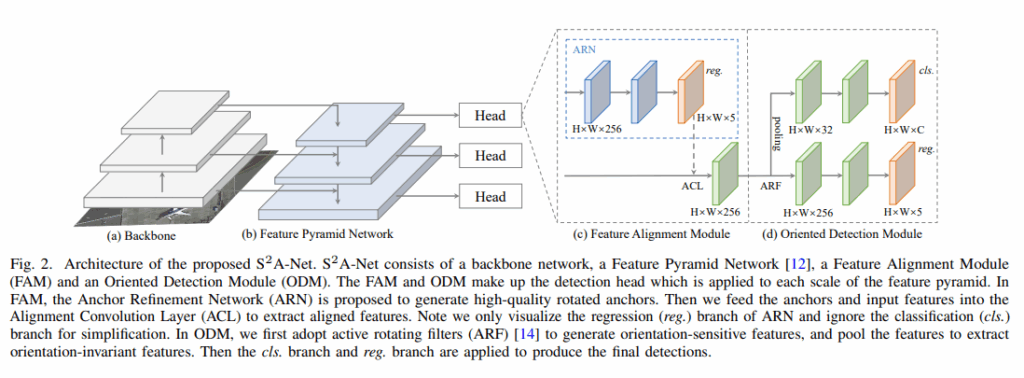
为了解决单阶段网络模型中的问题,提出了s2anet网络模型:该模型包含两个结构:Feature Alignment Module(FAM)在该结构中可以通过Anchor Refinement Network产生高质量的anchor并且能够自适应的将特征与anchor对齐以及Oriented Detection Module(ODM)在该结构中使用了active rotating filters (ARF)来编码方向信息,提取方向不变性的特征
本篇论文的贡献总结如下:
- 提出了Alignment Convolution结构使得提取的特征可以和物体对齐
- 基于上述基础提取了一个网络结构,能够帮助进行更好的处理
- 模型速度很快精度也很高
PROPOSED METHOD
RetinaNet as Baseline
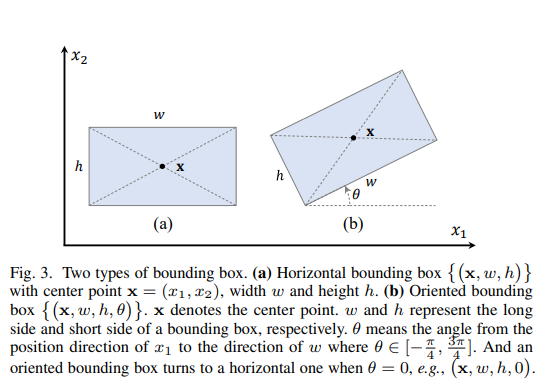
需要回归的形式为:
$$
\{(\pmb x,w,h,\theta)\}\quad\theta\in[-\frac{\pi}{4},-\frac{3\pi}{4}]
$$
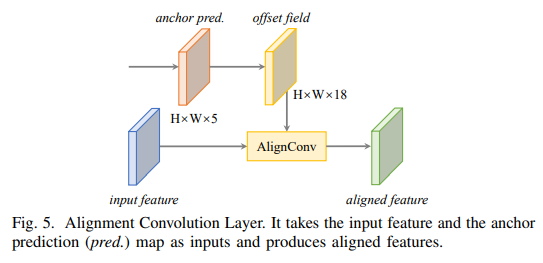
Alignment Convolution
标准卷积可以写为如下形式:
$$
Y(p)=∑_{r∈R}W(r)⋅X(p+r)
$$
其中p为输出的位置,r为相对中心点位置的偏移,而本次设计的Alignment Conv却和deform conv类似
$$
Y(p)=∑_{r∈R;o∈O}W(r)⋅X(p+r+o)
$$
不同的是这里的offset是基于anchor所计算出来的,举个例子来说明,假设在p位置的anchor为\((\pmb x,\pmb y, w,h,\theta)\),那么对于每一个\(r\in R\)采样位置可以被定义为:
$$
L_p^r=\frac{1}{S}(x+\frac{1}{k(w,h)} ⋅r) R^T (θ)
$$
Comparisons with other convolutions

Feature Alignment Module (FAM)
Anchor Refinement Network
上图的整体结构中,ARN结构中的分类分支没有画出来,该结构在检测大型分辨率图片的时候会被使用到,默认该分支是不使用的,并且跟随一对一的anhcor free迭代器一开始只设置一个方形的anchor。
Alignment Convolution Layer
Oriented Detection Module (ODM)
使用ARF来提取旋转敏感特征,之后通过pooling操作从旋转敏感特征中提取出任意方向不变性特征
$$
\hat{X}=maxX^{(n)},0<n<N−1
$$
Single-Shot Alignment Network
Regression targets
需要回归的目标如下:
$$
Δx_g=(x_g−x)R(θ)⋅(1/w,1/h)\\ (Δw_g,Δhg )=log(w_g,hg )−log(w,h)\\ Δθ_g=1/π (θ_g−θ+kπ)
$$
在FAM模块中设置角度为0
Loss function
$$
L=\frac{1}{N_F}(∑_iL_c (c_i^F,l_i^∗ )+∑_i1_{[l_i^∗≥1]} L_r (x_i^F,g_i^∗ ))\\+\frac{\lambda}{N_O} (∑_iL_c (c_i^O,l_i^∗ ) +∑_i1_{[l_i^∗≥1]} L_r (x_i^O,g_i^∗ ))
$$
前两个参数为正样本的数量,亮相的损失函数分别为Focal loss以及smooth L1。