TPH-YOLOv5
- CV
- 2021-10-23
- 508热度
- 0评论
TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios
Introduction
作者总结了无人机拍摄的数据集的几个难点:

- 物体的尺寸变化较大
- 高密集度
- 由于覆盖目标过大产生的透视几何畸变
所以本次模型backbone选择的是CSPDarknet53,Neck使用的是PAFPN
本次的模型可以进行如下的总结:
- 多加了一个检测头进行不同尺度的物体检测
- 加入了transformer预测头
- 将CBAM基础层到了YOLOv5模块中
- 使用了一系列的tricks以及排除掉了一系列没有太多用的trick
- 训练了一个小模型作为分类器
TPH-YOLOv5
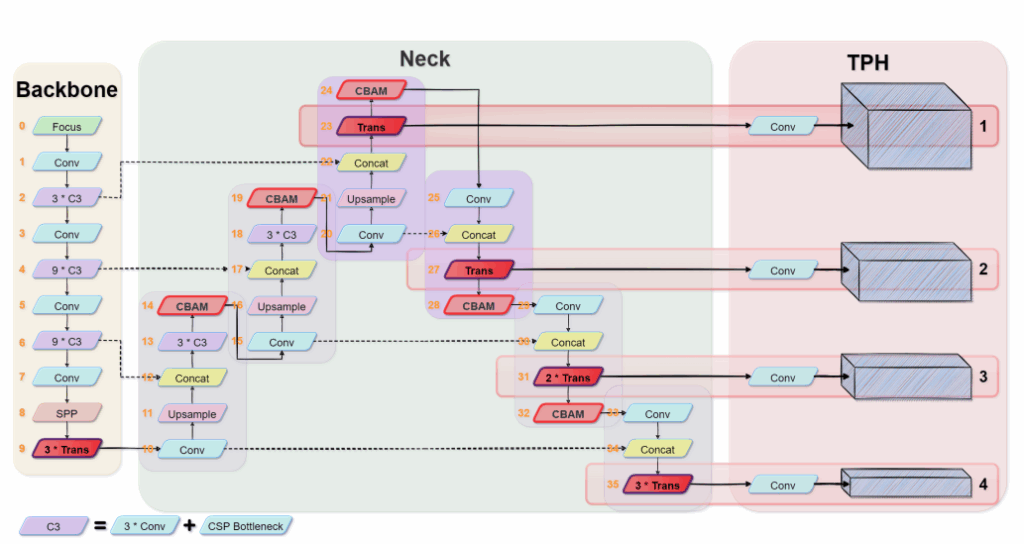
Overview of YOLOv5
基础模型使用的是yolox,neck选择的是PANET
TPH-YOLOv5
Prediction head for tiny objects
为了预测小目标,又额外在大尺度特征图上加了一个检测头
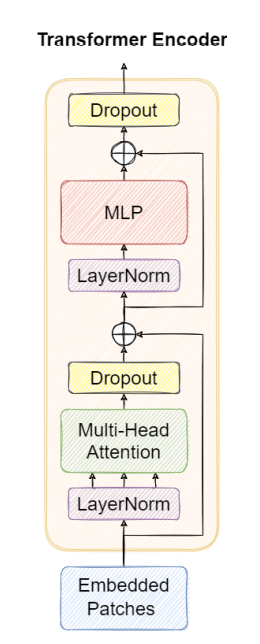
Transformer encoder block
由于作者相信transformer能够捕捉到更多的全局信息和上下文信息,所以得到的结构如下图所示:
Convolutional block attention module (CBAM)
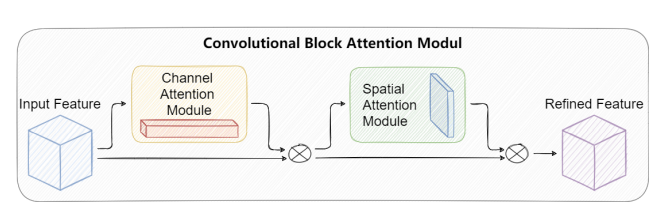
使用 CBAM 可以提取注意力区域,帮助 TPH-YOLOv5 抵御混淆信息,专注于有用的目标对象
Ms-testing and model ensemble
具体细节步骤:
- 缩放图片到原来的1.3倍
- 相对缩小图片到1倍,0.83倍,0.67倍
- 水平翻转
所以一张图片会变为6张图片进行测试之后再进行结果的融合
Self-trained classifier
由于有些类别很难分辨,所以又额外训练了一个分类器,backbone为ResNet18