Swinv2
- CV
- 2022-01-28
- 349热度
- 0评论
Swin Transformer V2: Scaling Up Capacity and Resolution
在本篇论文中,作者主要想解决的问题
视觉任务模型目前无法去像语言模型那样可以一直增大模型规模,当视觉模型参数量增大时,通常会遇到下面两个问题
- 模型的结果汇编的十分不稳定
- 许多下游任务需要输入大分辨率,而通过低分辨率预训练得到的模型是否能够帮助下游任务就变得未知了起来
所以作者针对上述问题对swin transformer做出了改进
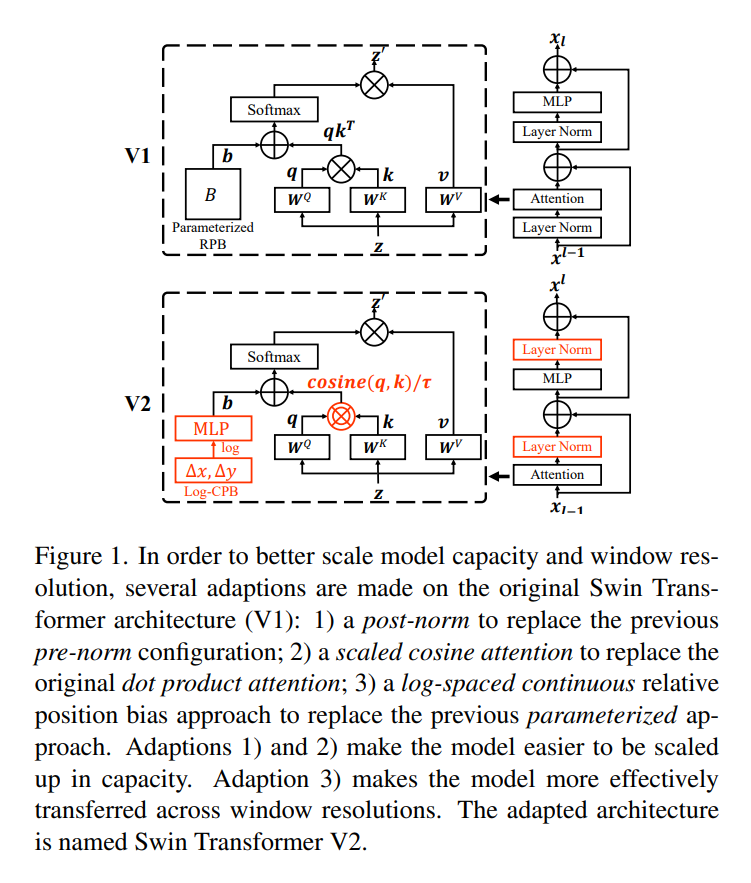
- 使用了postnorm并且scaled cosine attention
- a log-spaced 连续位置偏移来有效的将低分辨率预训练模型适配大尺度分辨率
Introduction
作者针对摘要的问题又进行了一定的解释:
首先作者发现随着网络层数的加深,跨层激活的幅度值差异很大,并且是随着层数的加深而逐渐变大的,所以作者使用了post-norm与cosine scaled去解决
其次由于预训练模型都是在低分辨率图片上进行的,下游任务的分辨率有些会很高,所以作者使用了对数空间坐标系,保证分辨率
Swin Transformer V2
Scaling Up Model Capacity
作者强调,在LN之后每个残差快的输出激活值都会直接合并回主分支,随着层数的加深,激活值会越来越大
Post normalization
所以只是把归一化的位置挪了一下,有意思的是其实detr就已经把norm的位置给挪动过了
Scaled cosine attention
作者发现某些模块的特征图上主要是几个点的像素值占了主导地位掩盖了其他点的特征值,所以得到了一下的公式:
$$
Sim(q_i,k_j )=cos(q_i,k_j )/τ+B_{ij}
$$
3.3. Scaling Up Window Resolution
引入对数空间坐标系
Continuous relative position bias
连续位置偏差方法在相对坐标上采用小型元网络
$$
B(Δx,Δy)=g(Δx,Δy)
$$
其中g是一个小型的网络,例如MLP
对于任意位置的相对坐标,它可以自然地迁移到具有任意变化窗口大小的微调任务
Log-spaced coordinates
当输入图片分辨率很大的情况下,窗口的大小也随之增大,这样位置嵌入就需要进行相应的扩展
$$
\hat{Δx} ̂=sign(x)⋅log(1+|Δx|)\\ \hat{Δy} ̂=sign(y)⋅log(1+|Δy|)
$$
预训练的时候就开始使用该模型,之后需要做的位置扩展嵌入就会少很多