T2T
- CV
- 2022-02-05
- 584热度
- 0评论
Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet
Introduction
作者认为现在的VIT有以下两种缺点:
- 直接词元化会导致ViT不能够对图片的局部特征,边缘和直线进行建模,这也是为什么transformmer需要大量数据集进行驱动的原因
- ViT包含大量每没有用的特征(全白或者全黑)

针对上述问题,作者给出了本文的两个贡献点:
- 提出T2T模块
- 发现类似于CNN的设计最终可以惠及transformer
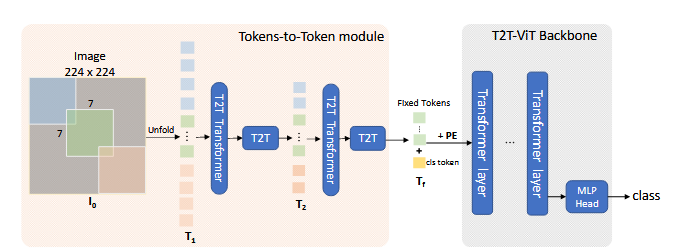
Tokens-to-Token ViT
Tokens-to-Token: Progressive Tokenization
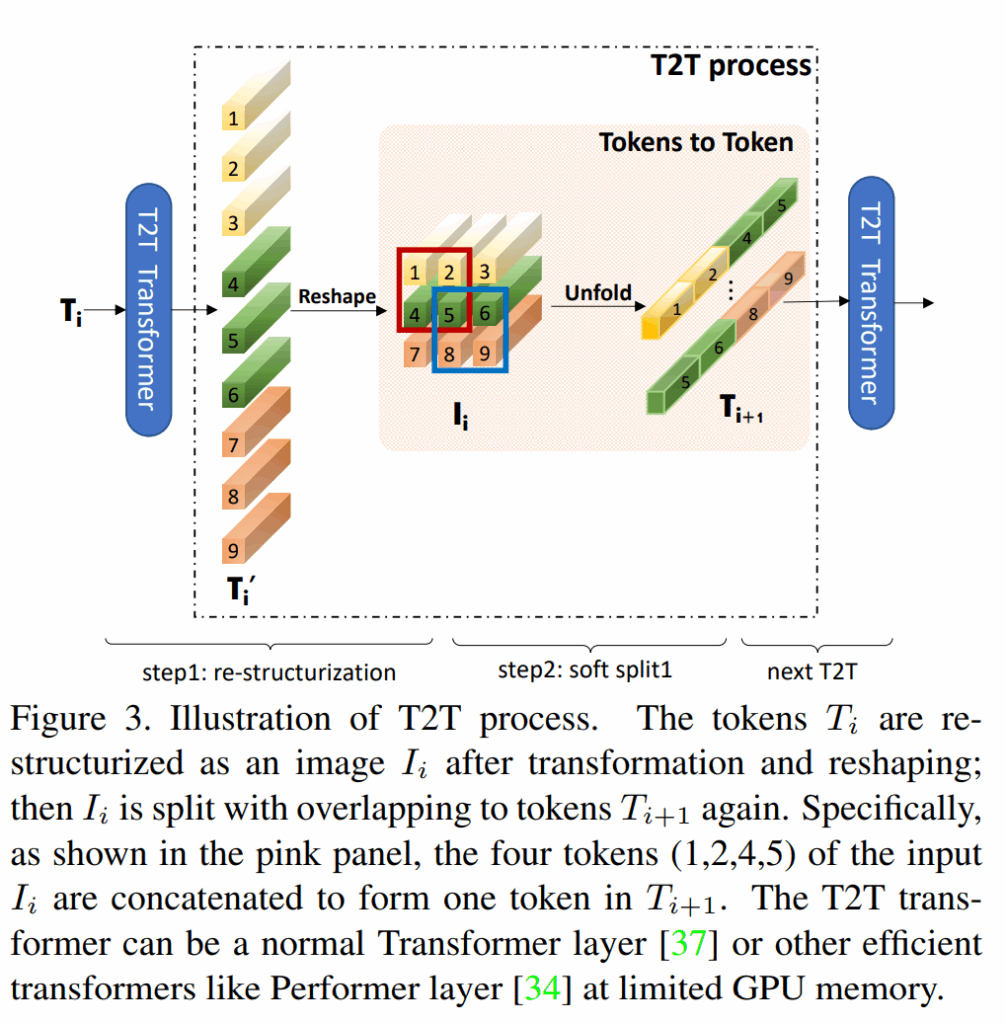
包含两个步骤
Re-structurization
首先模块经过attention模块
$$
T^′=MLP(MSA(T))
$$
之后进行重构,将token的空间尺度重新转换成原来的尺度
$$
I=Reshape(T^′ ),T^′∈R^{l×c},I∈R^{hw×c},l=h×w
$$
Soft Split
使用soft split来重构相邻结构的信息并且减少token的长度,这样每个patch就与相邻的patch产生了相关性,将每个patch的边长定义为k伴随着s的重叠与p的padding,那么最终输出的重构图的尺寸即为
$$
l_o=⌊((h2p−k)/(k−s)+1)⌋×⌊((w+2p−k)/(k−s)+1)⌋
$$
T2T module
$$
T_i^′=MLP(MSA(T_i ))
$$
$$
I_i=Reshape(T_i^′ )
$$
$$
T_{i+1}=SS(I_i ), i=1…(n−1)
$$
对于刚输入的特征图,首先就使用SS将其转换成token,最后一层将其的尺度转换成固定尺度,为了避免计算量和存储空间的占用通道数设置成了32或者64。
3.2. T2T-ViT Backbone
借鉴cnn的思想设置backbone,使用了五折不同的策略:
- DenseNet
- DeepNarrow vs shallow-wide
- SE
- ResneXt
- GhostNet
作者着重介绍了二三两种情况,第二种情况不论哪种提升都很大,第三种情况虽然有提升但是效率不高
之后将T2T与ViT结合,将T2T输出的结果与classtoken拼接后加上sinusoidal position embedding
$$
T_{f_0} =[t_{cls},T_f ]+E
$$
$$
T_{f_i} =MLP(MSA(T_{f_{i−1}}))
$$
$$
y=fc(LN(T_{f_b}))
$$