CCT
- CV
- 2022-02-08
- 775热度
- 0评论
Escaping the Big Data Paradigm with Compact Transformers
Introduction
文章的动机在于消除transformer需要大量数据驱动,所以作者的想法就是将CNN与transformer的结构结合起来。
所以本篇论文的贡献如下:
- 通过引入ViT-Lite来消除transformer需要数据驱动
- 引入Compact Vision Transformer(CVT)主要就是引入seq pooling
- 引入Compact Convolutional Transformer
Methodology
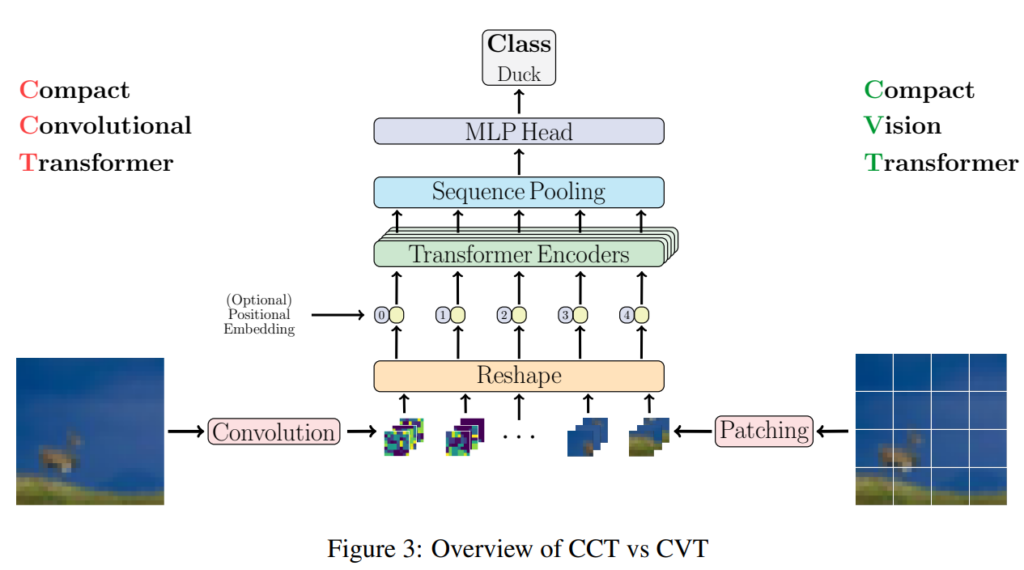
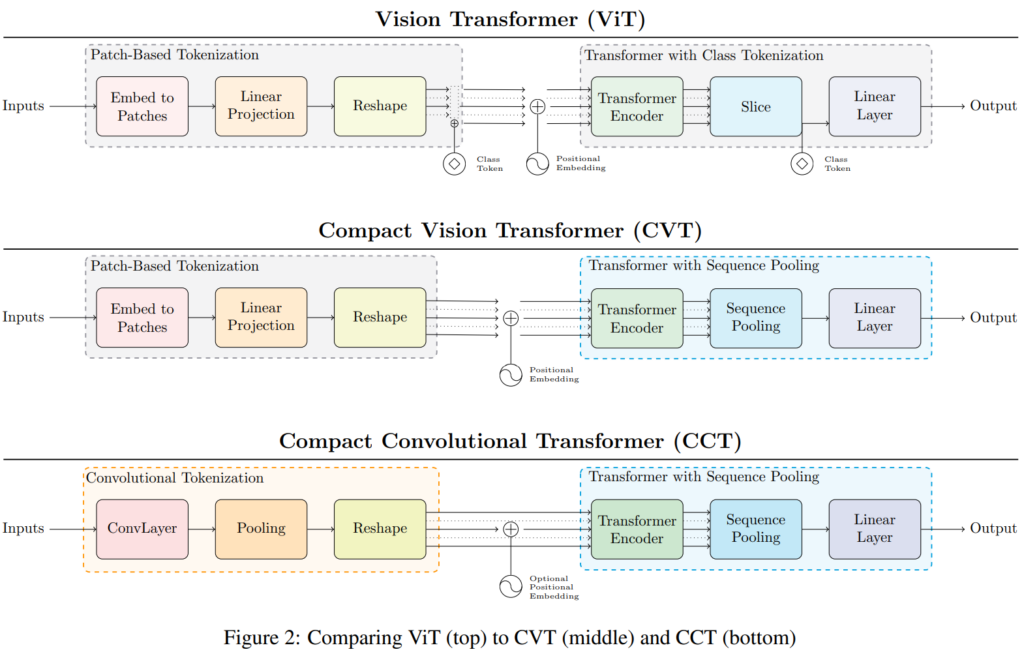
VIT-lite就是相当于普通的ViT但是patch的尺度更小
Convolutional Block
为了能够将归纳偏置引入模型中,将embedding patch转换成了卷积模块,好处是可以让输入的图像尺寸大小变得更加灵活。
公式表示为:
$$ x_0=MaxPool(ReLU(Conv2d(x))) $$
SeqPool
说白了就是将矩阵
$$
R^{b×n×d}→R^{b×d},g(x_L)∈R^{d×1}
$$
其中b代表的是batch size,n代表sequence length,d代表矩阵嵌入的维度。
具体的映射步骤为
$$
x_L^′=softmax(g(x_L )^T )∈R^{b×1×n}\\
z=x_L^′ x_L=softmax(g(x_L )^T)×x_L∈R^{b×1×d}
$$